How we cut token count by 11% and boosted success rate by 3.9% by using HTML instead of JSON in our LLM calls


TL;DR
We started using HTML instead of JSON to represent possible actions that Skyvern could take and reduced our cost by 11.8% and increased our success rate by 3.9%
What’s Skyvern?
Skyvern is an open source AI agent that helps companies automate browser-based workflows with AI. You can use Skyvern to automate actions on any website with natural language: simple objective-based problems. Examples include going to www.geico.com and prompting it with “generate an auto insurance quote”.
Github link here: https://github.com/Skyvern-AI/Skyvern
Try it out for yourself here: https://app.skyvern.com/
Book a demo here: https://meetings.hubspot.com/suchintan
What’s the problem?
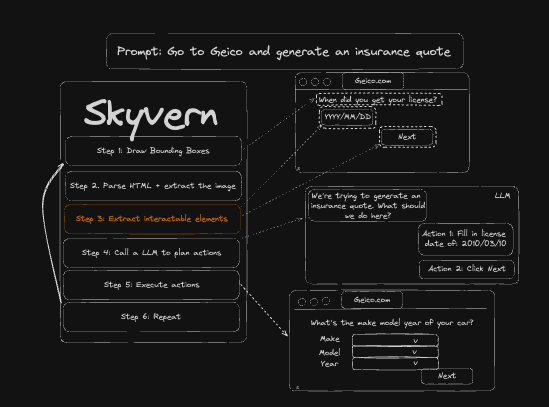
Skyvern identifies and annotates elements on the screen and generates metadata about the interactable elements. It sends both the an annotated screenshot + metadata about the interactable elements to a multi-modal LLM (such as GPT-4O or Claude 3.5 Sonnet) to decide what actions to take to accomplish a users’ goal.
Within that operation, a substantial portion of input tokens (our biggest expense) is consumed by the context associated with interactable elements
Specifically, Skyvern uses the annotated screenshot + a textual representation of the interactable elements to ground a LLM’s responses to reduce hallucinations (and therefore, increase accuracy) when interacting with random websites.
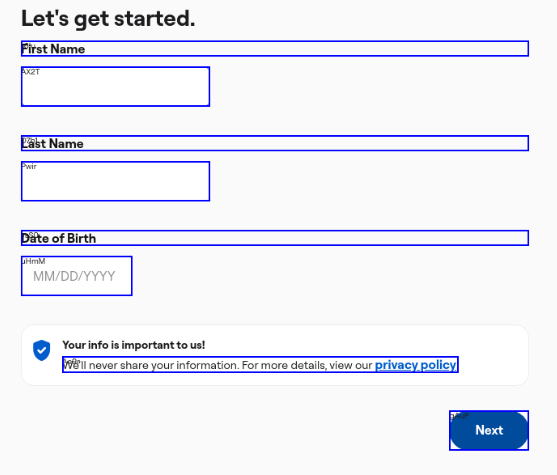
For the above screenshot, the grounded element tree includes elements that look like this:
{
"id": "Pwir",
"interactable": true,
"tagName": "input",
"attributes": {
"name": "Id_GiveLastName_21593",
"type": "text",
"maxlength": "20",
"aria-label": "Last Name"
},
"context": "Last Name"
},.
Given that token counts are highly coupled with operational costs, we wanted to explore alternative data representation methods.
We talked to some other founders in the space, and did some research and found that others’ had success using markdown & HTML to compress their prompts by over 15% over using JSON data [1]. Markdown wouldn’t be useful to us because we want to encode tag-related information (ie input) inside the information passed to the LLM.
Experimentation
Step 0: Do basic spot checks
Before digging too deep, we wanted to just do a spot check to assert that we expect data represented as HTML takes fewer tokens than JSON. [OpenAI tokenizer]
Sample Prompt + Element Tree (HTML):
// number of tokens: 31
<input id="Pwir" name="Id_GiveLastName_21593" type="text" maxlength="20" aria-label="Last Name">
Sample Prompt + Element Tree (JSON):
// number of tokens: 70
{
"id": "Pwir",
"interactable": true,
"tagName": "input",
"attributes": {
"name": "Id_GiveLastName_21593",
"type": "text",
"maxlength": "20",
"aria-label": "Last Name"
}
}
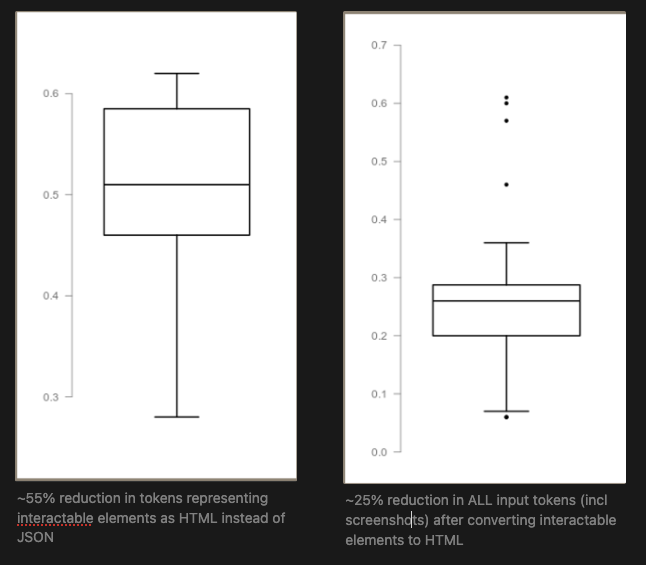
Expanding this to a set of past Skyvern tasks, we can see that representing our data as HTML will reduce our result in approximately 20-27% Savings
Step 1: Test in production
The primary goal of this experiment was to reduce operational costs without compromising the performance of Skyvern. To achieve this, we conducted an A/B test in production using this new set-up
For the A/B test, we divided tasks evenly between the original JSON representation and the new HTML representation. We tracked the success and failure rates of each approach on customer tasks, which is how our users derive value from Skyvern.
Step 2: Look at the test Results
We ran the test on over ~1,100 tasks within Skyvern. Here’s the final breakdown:
| Experiment | Status | Number of tasks | Net cost (p50) | Success rate |
|---|---|---|---|---|
| HTML | success | 332 | 1.08 | 63.8% |
| failed | 188 | 2.82 | ||
| JSON | success | 391 | 1.22 | 59.9% |
| failed | 261 | 3.13 |
- Success Rate Impact:
- Overall, a 3.9% improvement in success rate
- JSON representation: 59.9% success rate
- HTML representation: 63.8% success rate
- Cost Impact:
- Overall, a 11.4% reduction in net cost
- JSON representation: 1.22 average cost per task
- HTML representation: 1.08 average cost per task
Counterintuitive learnings
We accomplished the goal we set out to do. We reduced our operating costs by 11.4%. YAY!
But.. something counter-intuitive also happened: we also improved our success rate. Why?
Our working hypothesis is that by cutting down the total context we’re sending to an LLM, we’ve reduced the rate of hallucinations that long context windows can provide [paper]